| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Kernel regression
- pandas
- Word Embedding
- 우박수
- abcd
- CodeUp
- 코드업
- Python
- 판다스기초
- DCCSAE
- RSFC-based behavioral prediction
- cortical mapping
- 광화문텀블러
- SPM12
- cortical representation
- 파이썬
- Slice timing
- Realignment
- matlab
- Coregistration
- SPM
- 판다스
- DMN
- socioeconomic status
- 한정판텀블러
- 약수구하기
- fMRI
- Normalise
- neurofeedback
- hierarchical clustering analysis
- Today
- Total
몽발개발
Pandas? 그게 뭐에요? 파이썬 초심자를 위한 pandas 간단 설명 본문
전의 게시글에서는 python의 기본 라이브러리인 numpy에 대해서 살펴보았다.
그 numpy와 함께 붙어다니는, 데이터를 다루는 쪽의 연구나 일을 하면 빼놓을 수 없는 또 다른 라이브러리가 바로 pandas이다.
실제로 내 체감상 비전공자(참고로 난 생명과학부이다)의 학부수준에서 파이썬 실력은 numpy와 pandas를 얼마나 자유자재로 다루느냐가 좌지우지한다고 생각한다.
그럼 pandas는 왜 유용할까?
초등학교 때 엑셀을 사용한 경험이 있을 것이다. 우리가 흔히 접하는 통계자료나 데이터들은 엑셀같이 블록 하나 하나 값이 채워져 보기 쉽게 만들어져 있다.
파이썬에서도 이러한 표처럼 생긴 데이터를 가져올 수 있다. 우리가 얻은 데이터를 파이썬으로 불러와 용도에 맞게 씹고 뜯고 바꾸고 채우고 할 수 있는 도구가 바로 pandas라는 것!
그렇기 때문에 이 pandas만 알아도, 내가 원하는 데이터를 가져와서 확인하고, 여러가지 통계적 수치들을 확인할 수 있다.
그래서 pandas를 배우면서 새로운 파이썬의 세상에 눈을 뜬 것 같았다고...!
그럼 바로 pandas를 써보자.

Numpy를 np로 불러오는 것처럼, pandas는 6글자라 너무 귀찮으니 두글자인 pd로 부르자.

엑셀같은 표를 DataFrame, 그리고 하나의 세로열로만 이루어진 데이터를 Series라고 한다.
얘가 DataFrame이고,
얘가 series!

list를 만들어, 그 리스트를 Series로 바꾸었다.

이렇게 Series가 만들어졌다.
어? 이건 두줄인데요? 라고 생각할텐데, 맨 첫 줄은 index라고하여, 자료에 매겨진 번호라고 생각하면 된다.
학교에서 우리 이름이 데이터라면, 출석번호가 index인 것이다.

좀 더 본격적인 데이터를 만들어보자.
딕셔너리형으로 데이터프레임 안에 들어갈 수치들을 적어보았다.
과연 결과는 어떻게 나올까?

짜잔~ 익숙한 엑셀 형태의 데이터가 나왔다. 한눈에 보기에도 데이터를 다룰 때 편하게 생겼다.
사람마다 다르겠지만 나는 실제로 데이터를 만드는 일보다, 이미 존재하는 데이터를 가져와서 쓰는 경우가 훨씬 많았다.
그리고 아마 학부 수준에서 다루는 데이터는 다 만들어진 데이터를 쓸 것이기 때문에, 만들어진 데이터를 불러오는 기능부터 소개하고 싶다.
😁😁😁read_csv,read_excel😁😁😁
판다스의 기본적인 데이터 불러오는 함수는 read_csv, read_excel이다. 각각 csv파일과 excel파일을 불러올 수 있다.

판다스의 기능이기 때문에 앞에 pd(앞에서 이미 import pandas as pd했으니)를 쓰고 .read_csv를 해서 내가 원하는 데이터를 불러와보았다. 참고로 현재 진행중인 학부 프로젝트에서 쓰는 raw data이다.
기본적인 형태는 pd.read_csv(" 내가 불러올 파일 경로 ") 이런 식으로 쓰면 된다. 엑셀파일은 read_csv 대신 read_excel을 넣으면 완성이다.
그렇다면 불러온 데이터를 한번 보자. 데이터의 출처는 tomslee에서 받은 서울의 에어비엔비 자료이다.

자세히 보면 나는 data1만 입력한게 아니고 data1.head()를 입력했다.
.head()는 데이터의 앞에서 몇번째까지만 나타내주는 기능이다. 데이터가 클 경우에는 한번에 다 볼 필요 없이, 제대로 불러와졌느냐/무슨 수치들이 들어있느냐를 확인하는게 우선이기 때문에 head()를 사용하여 데이터의 형태를 확인한 것이다.
head() 괄호 안에 숫자가 들어가면 시작부터 그 숫자만큼의 행을 표시한다. 기본적으로 head()만 입력할 경우에는 위에서부터 5개의 행을 보여준다.
😁😁😁전체적인 데이터 갯수 파악😁😁😁
데이터가 생각보다 길어 뒤에가 짤렸다. 이 표의 column의 구성을 알고싶다면 단순히 .columns 기능으로 모아서 볼 수 있다.

이 데이터는 이렇게 총 14개의 column들로 이루어져 있다.
그럼 전체 subject(가로행) 수는 얼마나 될까?
어차피 subject가 누구인지는 우리가 봐도 모르고, 중요한 건 '몇 개'인가 하는 숫자다.
그럴때도 이 pandas는 좋은 기능이 있다.

.shape를 데이터프레임 뒤에 붙이면 이렇게 행과 열의 수를 알려준다.
이렇게보니 데이터는 전체적을 8519개의 행(subject)과 14개의 column들로 이루어진 표인 것을 쉽게 알 수 있다.
😁😁😁Nan😁😁😁
와! 이제 우린 이 데이터를 바로 써서 이것저것 할 수 있을 꺼야!
하지만 현실은 그렇게 녹록치가 않다.

데이터를 살펴보니 NaN이라고 써있는 게 많다. 이게 뭘 나타내는 걸까?
바로 Not a number의 약자로, '알려지지 않은 값' 이란 뜻이다. 결측데이터인 것이다.
우리가 이런 결측값이 어디 얼마나 있는지 일일히 찾을 순 없기에, pandas의 기능을 사용해 전체적인 NaN이 몇개나 있는지 알아보자.

.isnull()을 입력하면 표의 그 칸이 NaN인지, 실제 값이 있는지 True/False로 나타내준다.
그래봤자 어차피 눈에 안띄기 때문에 우리에게 필요한 결측값의 갯수들의 합을 구하기 위해 .sum()을 또 붙여준다.
확인해보니 각 column마다 NaN이 몇개나 있는지 나왔다.
Subject 수가 8519개였는데, 그게 전부다 NaN인 column도 있고, 절반이상이 NaN인 column도 있다.
데이터를 다루는 때에는 이런 NaN값을 어떻게 처리할지도 자신이 결정해야 한다.
하지만 지금은 그럴 때가 아니니 넘어가자. 혹시 결측값을 채우는, 혹은 지우는 법을 알고싶으면 구글에 fillna나 dropna를 치면 자세히 설명한 글들이 많다.

참고로 sum() 괄호안에 1을 넣으면 가로행들의 NaN갯수가 나온다. 다른 기능에서와 마찬가지로 sum()안의 숫자는 axis이며, 기본적으로는 0으로 설정되어있어 sum()처럼 아무것도 안쓰면 세로열 기준으로 처리된다.
😁😁😁인덱싱. loc, iloc😁😁😁
이 큰 데이터에서 내가 원하는 데이터만 뽑고싶은데요?
사실 아마 이 pandas를 만들어낸 사람도 그려려고 만들어낸 것이 아닐까? 할만큼 pandas로 구현이 매우 잘되어있다.
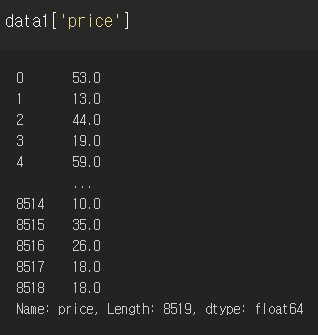
우선 데이터프레임에서 자신이 원하는 column만 series로 따로 빼내서 보고싶을 때에는 그냥 ['column이름']을 입력하면 된다. 나는 data1의 price 열만 보고싶어 이렇게 빼왔다.
근데 이게 끝이면 pandas를 지금까지 사용하지 않았을 것이다.
여기서 한층 더 들어가서, 우리가 필요한 행과 열을 뽑아낼 수 있다.

만약에 우리가 데이터에서 3번째 subject의 neighborhood의 값을 알고 싶다면, 두 가지 방법으로 뽑아낼 수 있다.

프린트된 결과를 보면 같은 값인 걸 알 수 있다.
.iloc는 뒤에 [숫자,숫자]로 인덱싱을 하고, .loc는 뒤에 [인덱스,column이름]을 받는다.
데이터가 커질수록 내가 어떤 데이터가 몇번째인지 세고있을 시간은 없기 때문에 많은 경우에는 그냥 .loc를 쓰게 된다.
😁😁😁조건이 맞는 데이터만 뽑아내기😁😁😁
여기에 한 술 더 떠서, 우리가 원하는 조건을 가진 데이터만 뽑아낼 수 있다.
무슨 소리냐고?

앞에서 말했듯이 .loc는 [인덱스, column이름] 을 받는다고 하였다.
그리고 인덱스 자리에 data1['price']>70 을 넣음으로써,
'나는 data1에서 price가 70 이상인 subject만 볼꺼야' 라고 말한 것이다.
그리고 뒤에 column에는 'neighborhood'넣어서, 나는 "가격이 70 넘는 에어비엔비 방"이 "어느 동네에 가까운지" 볼 수 있다.

value_counts()를 붙이면 이렇게 같은 값을 가지는 애들의 갯수까지 알 수 있다.
가격 70넘는 애들은 역삼동,동교동,서교동 주변에 있구나! 이런 식으로 데이터의 흐름을 파악할 수 있게 되는 것이다.
😁😁😁
판다스에 대해 열심히 적다보니 간단하게 적는다면서 생각보다는 긴 글이 되었다.
기본적인 것에다가 엄청 부실해서 잘하는 사람이 보면 뭐 이런 글을 적었어 할 수도 있지만,
내가 진짜 아무것도 모르던 때를 생각하며 최대한 초보적인 입장에서(지금도 초보지만) 설명을 적었다.
어차피 판다스의 모든 기능을 쓰지는 않을 꺼지만, 위 사항들은 내가보기에 누구나 판다스를 쓰게 된다면 쓰는 기능들이다! 그리고 이외에 필요한 기능이 있는데 어떻게 쓰는지 모르겠다면, 그때그때 구글링하자. 왠만하면 다 있다.
많이 쓰면 많이 익숙해지고, 실력이 는다. 그게 언어고 c언어도 예외는 아니다.
'파이썬(Python) > 머신러닝,딥러닝' 카테고리의 다른 글
| Numpy? 그게 뭐에요? 파이썬 초심자들을 위한 numpy 간단소개 (0) | 2020.11.02 |
|---|
